快速了解:MMBench
是什么:多模态模型性能评估基准
适合
关注 大模型、大模型评测 相关场景的用户;主要在 全球用户 下使用 AI 工具的用户
注意
若你期望完全离线、私有化部署且不接受任何联网服务,请优先评估企业版或自建方案。
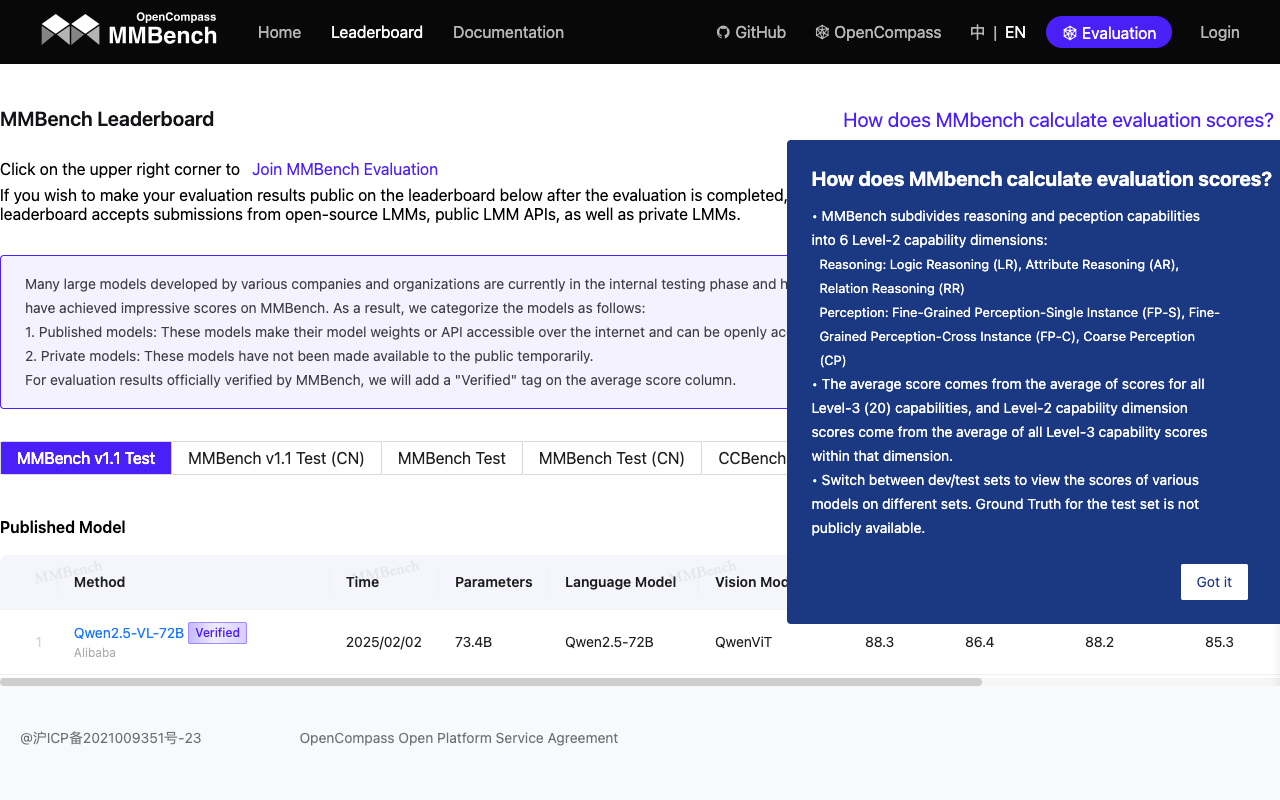
https://mmbench.opencompass.org.cn/leaderboard 是 MMBench 的官方排行榜页面,由 OpenCompass 社区维护。MMBench(Multi-Modal Benchmark)是一个多模态基准测试平台,旨在评估大型视觉-语言模型(Vision-Language Models, VLMs)的多模态理解能力。该排行榜展示了不同模型在 MMBench 测试集上的性能表现,为研究人员、开发者以及 AI 社区提供了一个直观的比较平台。
网站功能与内容
-
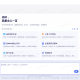
模型性能排行榜
-
评测维度
- MMBench 涵盖约 3000 道多选题,涉及 20 个细粒度能力维度,例如目标检测、文字识别、关系推理、逻辑推理等。
- 排行榜可能展示模型在这些具体任务上的表现,帮助用户了解模型的强项和短板。
-
数据提交与更新
- 开发者可以通过提交评测结果参与排行榜,提交方式通常是将模型输出文件(如 Excel 格式)上传至指定链接(例如 https://mmbench.opencompass.org.cn/mmbench-submission)。
- 排行榜会定期更新,以反映最新的模型性能和技术进步。
-
可视化与对比
- 网站提供直观的表格或图表形式展示数据,便于用户对比不同模型。
- 用户可以筛选或排序数据,查看特定模型或能力的详细信息。
使用场景
- 研究与开发:研究人员利用排行榜数据评估模型性能,优化算法。
- 模型选择:开发者可根据排行榜选择适合其任务的模型。
- 社区贡献:鼓励用户提交新模型结果,共建开源评测生态。
如何访问与使用
- 直接访问 https://mmbench.opencompass.org.cn/leaderboard 查看最新榜单。
- 若需参与评测,可参考 OpenCompass 的 GitHub 页面(https://github.com/open-compass/MMBench)或官方文档获取详细说明。
这个排行榜是多模态 AI 领域的重要资源,体现了 MMBench “评估全方位多模态模型能力”的目标。