SWE-agent:让 LLM 自动修 GitHub Issue 的智能体框架
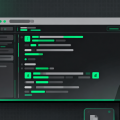
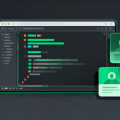
开发者最头疼的日常之一:打开 Issue 列表,面对一堆复现步骤和报错日志。SWE-agent 直接把 LLM 变成了能读代码、写补丁、跑测试的“虚拟工程师”——给定一个 GitHub Issue,它能自主理解仓库结构、编辑文件、执行命令,最终提交修复 PR。适合想用 AI 自动化代码维护的团队、研究 LLM 工具调用能力的开发者,以及任何被 Issue 淹没的开源维护者。核心看点- 端到端 Issue 修复:输入 Issue 链接,智能体会自动克隆仓库、定位相关文件、生成 diff 补丁,甚至尝试运行测试验证修复是否正确。实测在 SWE-bench 基准上达到 12.3% 的解决率(2024 年初数据),远超之前的方法。 - 可定制的 Agent-Computer 接口:框架将 LLM 与 Linux 环境(bash、文件系统、编辑器)解耦,你可以替换底层模型(GPT-4、Claude 等),或自定义工具集——比如只允许读取代码而不允许执行。 - 完整的反馈循环:每次代码编辑后,Agent 会读取错误输出或测试结果,迭代修改直到通过。整个过程透明可追溯,所有交互日志都保存在本地。▲ github.com(阿里云通义万相生成配图,非网页截图)适合谁- 想用 LLM 自动化代码 BUG 修复的团队,需要 README 中的 Docker 环境(无需 GPU,但推荐 16GB+ RAM)。 - 研究 Agent 工具调用与规划的研究者,仓库提供了详细的论文复现脚本和评估数据集。 - 注意:目前主要面向 Python 代码库,且需要 GitHub 令牌(用于克隆仓库)和 OpenAI / Anthropic API Key。想立刻让 LLM 帮你修一个 Issue?直接访问仓库首页 SWE-agent,用 pip install sweagent 开始体验。别忘了先看 examp…