阅读要点
先读这里,快速了解全文在讲什么
核心结论
开源语音模型(Coqui TTS、XTTS-v2)让个人开发者能以极低成本提供AI语音克隆与配音服务,适合有声书、播客、短视频等垂直场景,变现路径清晰,门槛低。
你可以了解到
阅读后可获得与「个人开发者与小团队如何用开源语音模型打造垂直场景AI配音副业」相关的实用信息与站内延伸资源;最后更新 2026年5月5日。
延伸阅读
当大模型创业的聚光灯打在视频生成、Agent平台和代码助手时,一个被低估的赛道正悄然成熟——AI语音克隆与配音。2026年,开源语音模型如Coqui TTS、XTTS-v2、OpenVoice等已能实现10秒音频样本的实时语音克隆,且推理成本降至单次0.01元以下。对于个人开发者或小团队,这可能是当前门槛最低、变现路径最清晰的AI副业方向之一。
为什么是语音克隆?三个核心优势
- 技术成熟度与成本双优:开源模型(如Coqui TTS)支持中文多说话人合成,无需GPU即可在CPU上运行;API成本仅为商业TTS服务的1/5。
- 需求碎片化且付费意愿强:有声书、播客、短视频配音、游戏NPC语音、教育课程旁白——每个场景都需要“像真人但不贵”的语音。中小主播、自媒体作者、独立游戏开发者是典型付费客户。
- 竞争壁垒低但粘性高:一旦为某个客户定制了品牌声线(如“某播客专属男中音”),复购和转介绍自然发生。
三种可落地的玩法
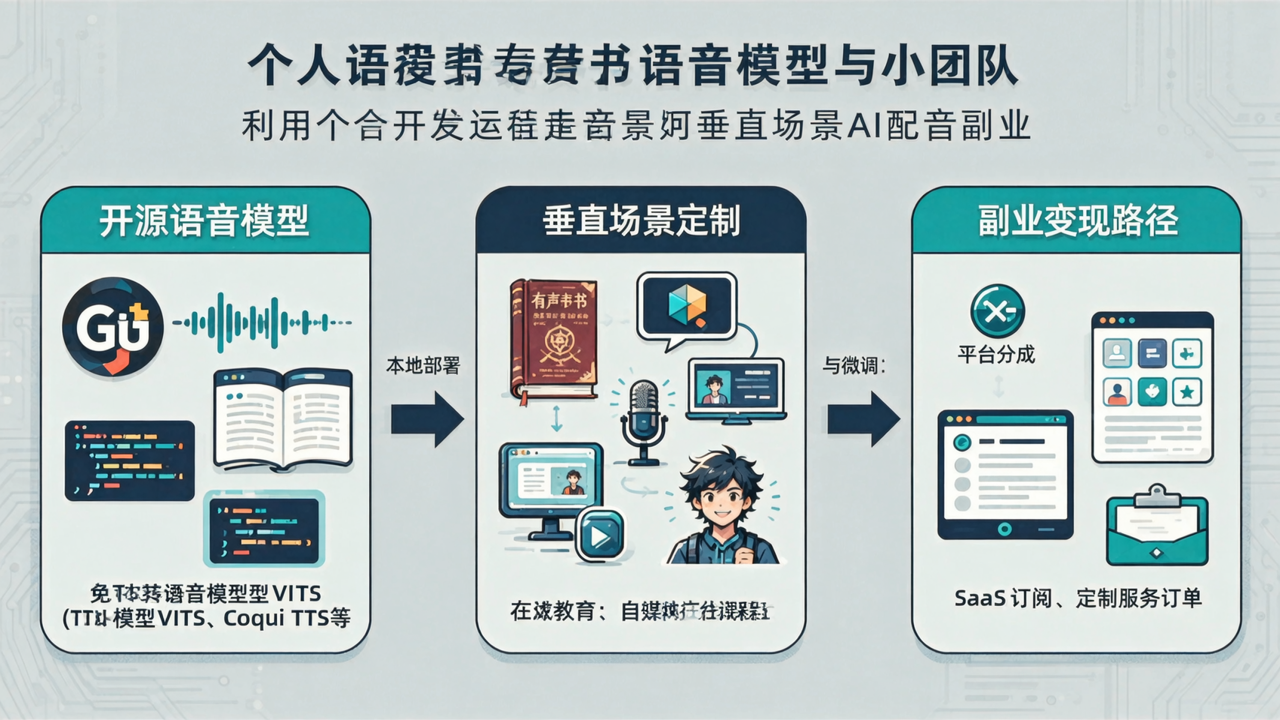
- 垂直场景配音服务:聚焦有声书或播客。用OpenVoice或XTTS-v2为作者提供“克隆自己声音”的旁白录制服务,收费按分钟或按项目。第一步:在Fiverr、猪八戒或小红书发布案例,展示10秒样本即可。
- 本地化语音工具包:针对中小企业,打包“语音合成+情感控制+多语言”的轻量API。例如为跨境电商卖家生成多语种产品介绍视频配音。使用Coqui TTS+FastAPI搭建,一天内可出MVP。
- AI语音定制平台:面向个人用户,提供“上传10秒录音→生成专属语音模型→在线合成任意文本”的SaaS。按模型数量或合成字数收费。推荐用Hugging Face Spaces或Replicate部署。
第一步行动建议
本周内完成:1)本地搭建Coqui TTS或XTTS-v2环境(GitHub仓库有完整教程);2)录制一段10秒中文语音样本,生成3条不同情绪(平静、兴奋、悲伤)的合成音频;3)在小红书/知乎发布对比视频,标题如“我用开源模型克隆了自己的声音,效果惊人”。如果一周内获得20+咨询,说明需求真实,可启动收费服务。
适合人群:有Python基础的独立开发者、想低成本试水AI副业的个人、小团队(2-3人)可分工模型调优与客户对接。注意:涉及他人声音克隆时,务必获得书面授权,避免法律风险。