快速了解:OpenCompass司南 – 评测榜单
是什么:大模型性能权威评测榜单
适合
关注 大模型、大模型评测 相关场景的用户;主要在 全球用户 下使用 AI 工具的用户
注意
若你期望完全离线、私有化部署且不接受任何联网服务,请优先评估企业版或自建方案。
想了解哪个大语言模型更强?OpenCompass LLM排行榜提供了一个清晰的答案。这个由社区维护的开源榜单,就像大模型界的“成绩单”,用超过100个测试题目给模型们打分排队。
榜单里有什么
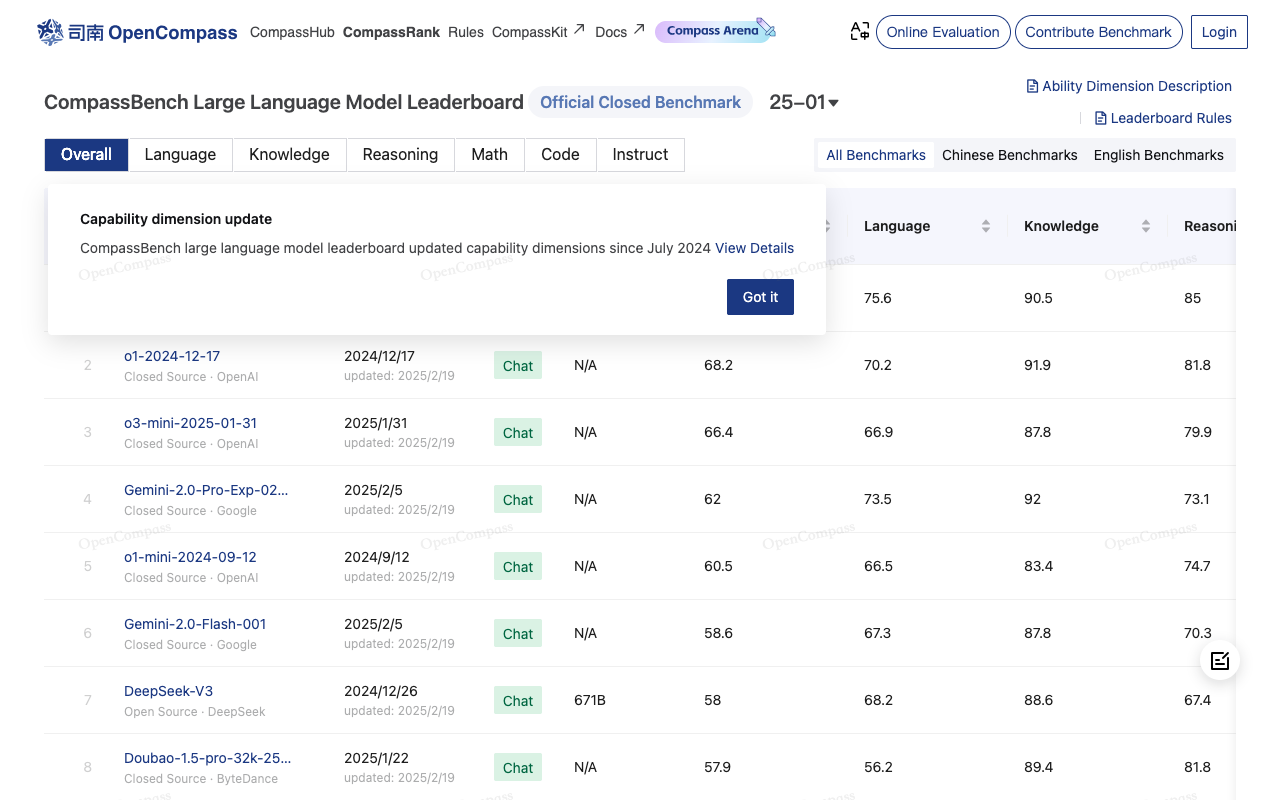
打开榜单,你会看到一长串熟悉或陌生的模型名字,从开源的LLaMA、Qwen,到需要付费的GPT-4、Claude,都按综合得分排好了座次。这个分数不是随便给的,它来自一套严格的考试:既有考验常识和知识的MMLU-Pro,也有烧脑的逻辑题BBH,还有让人头疼的数学题MATH-500和编程挑战HumanEval。可以说,模型们在这里经历了全方位的“素质”考核。
如何参与与查看
榜单是动态更新的,反映了模型界的最新战况。比如,2024年9月,阿里云的Qwen 2.5-72B-Instruct就曾作为首个开源模型登顶,分数超过了当时的Claude 3.5和GPT-4o。如果你自己训练了一个模型,想看看它到底什么水平,也可以按照平台指南,通过邮件提交模型参与评测。
对于研究人员,这份榜单是分析模型强弱、寻找改进方向的重要工具;对于开发者,则是根据具体任务(比如需要强推理还是擅长写代码)挑选合适模型的实用参考。访问排行榜页面可以查看最新排名和详细数据,所有评估方法和部分配置也可以在GitHub上找到,保证了过程的透明和可复现。