快速了解:PinchBench
是什么:AI模型基准测试平台
适合
关注 OpenClaw(龙虾)、热门领域 相关场景的用户;主要在 全球用户 下使用 AI 工具的用户
注意
若你期望完全离线、私有化部署且不接受任何联网服务,请优先评估企业版或自建方案。
同类备选
- Lista:实时潜在客户识别与人才搜索工具 实时识别潜在客户与人才
- Nullity AI:团队内部知识库与搜索引擎 团队知识库智能搜索引擎
- Sound Effect Generator:AI 文本生成音效工具 文字秒变音效的AI工具
PinchBench是Kilo AI团队打造的AI大模型Agent能力专业评测平台,也是业内首个聚焦OpenClaw智能体框架适配性的实时评测基准工具。它的核心定位是检验大模型在真实工作流中执行能力的“试金石”。
与传统评测只关注知识问答或数学推理不同,PinchBench专注于验证模型能否完成端到端的实际任务。平台从成功率、速度、成本三大核心维度对全球主流大模型进行量化排名,为开发者选择适配OpenClaw的模型提供精准参考。所有数据实时更新且完全开源。
平台背景与开发团队
PinchBench并非出自大厂,而是由专注于Agent基础设施的创业公司Kilo AI开发。该团队由GitLab前联合创始人兼CEO Sid Sijbrandij投资并参与创立,曾推出“氛围编程”工具Kilo Code和基于OpenClaw的全托管智能体平台KiloClaw。
随着OpenClaw智能体框架的流行,开发者面临“选哪个大模型适配”的难题。大模型调用既耗成本,又要求速度,不同模型的实际执行能力差异显著。Kilo AI顺势推出PinchBench,作为KiloClaw的配套评测工具,旨在解决智能体开发的模型选型痛点。
核心定位与价值
核心定位
PinchBench是AI智能体的专属能力评测基准,聚焦大模型在OpenClaw框架下的实际任务执行能力,而非单纯的模型推理能力,堪称连接大模型与智能体落地的“选型指南针”。
核心价值
- 解决选型痛点:从成功率、速度、成本三维度量化排名,让开发者无需自行测试,直接找到适配OpenClaw的高性价比模型。
- 评测贴近实际:基于真实工作流设计测试任务,结果能直接反映模型在实际智能体开发中的表现。
- 实时更新数据:评测榜单随模型迭代、测试优化实时更新,保证参考性。
- 完全开源可定制:用户可在平台自行运行测试、添加新任务,适配个性化需求。
- 国产模型参考:榜单中国产大模型表现亮眼,为国内开发者选择本土模型提供依据。
核心评测体系
PinchBench的优势在于评测逻辑贴近智能体的实际落地场景,其体系包含测试任务、评分机制、核心指标三部分。
一、测试任务:基于真实工作流
平台摒弃传统的“单一问题问答”,设计了约23个贴近实际的端到端任务,模拟智能体在工作中的真实操作,包括:
- 信息类:查询并整理多源资料、提取文档核心信息。
- 创作类:写商务邮件、生成数据报告、撰写操作说明。
- 操作类:调用第三方API、生成并执行简单脚本、处理跨平台数据同步。
所有任务均要求模型完成完整的工作流,真正考验其“行动能力”。
二、评分机制:客观量化
采用双重评分体系:
- 自动化检查:针对有明确结果的任务,通过脚本自动验证,直接判定“完成/未完成”。
- LLM评审:针对无固定答案的创意/分析类任务,由专业大模型从内容质量、贴合需求等维度打分。
最终分数为模型的任务完成成功率。
三、核心评测指标
围绕智能体开发的实际需求,设置三大核心指标:
- 成功率:模型完成标准化测试任务的百分比,反映实际执行能力。
- 速度:模型完成任务的平均耗时,影响用户体验。
- 成本:模型完成任务的平均Token消耗,帮助控制运营成本。
平台还提供预算筛选功能,可按“单次运行最大成本”过滤模型。
平台功能与展示
一、核心功能
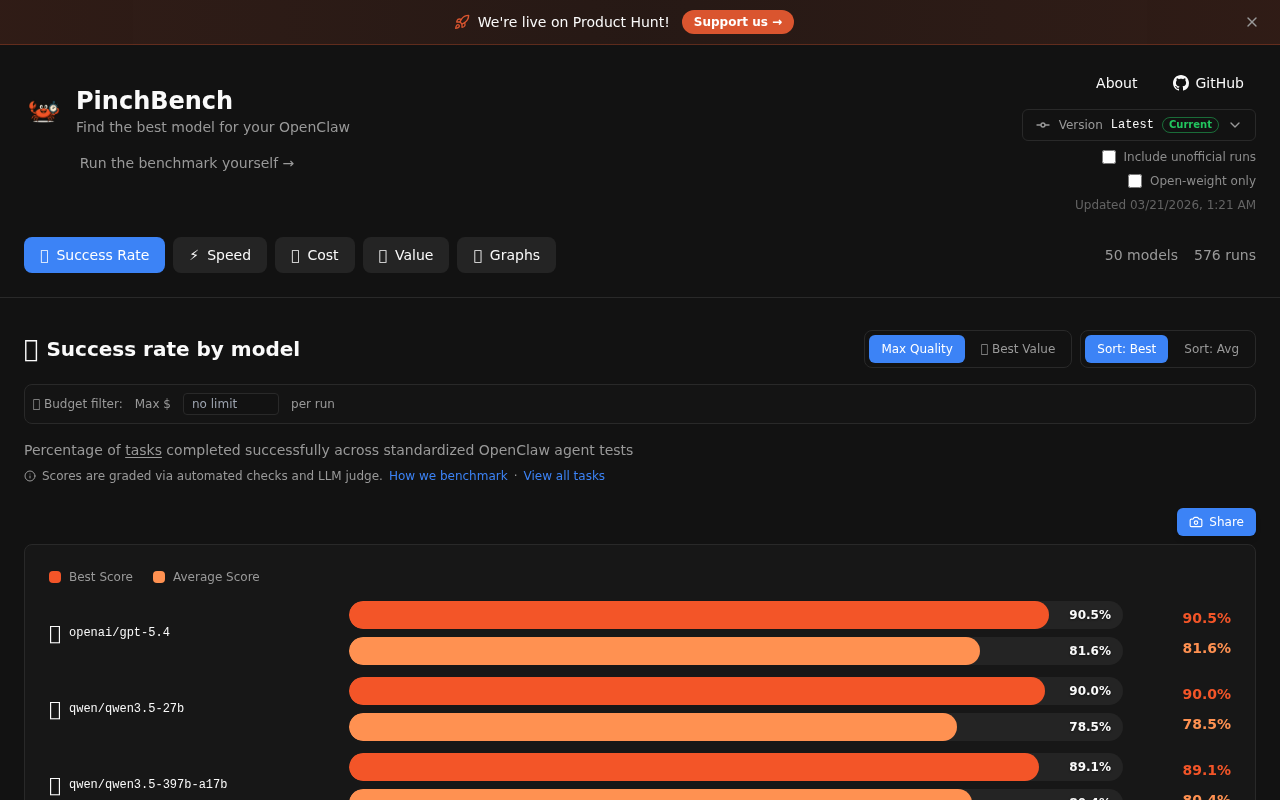
- 实时评测榜单:展示全球主流大模型的OpenClaw适配性排名,按成功率排序。
- 多维度筛选:支持按预算、模型提供商、版本等条件筛选。
- 开源测试能力:用户可自行运行标准化测试或添加自定义任务。
- 模型详情展示:每个模型标注提供商、成功率、综合得分,部分优质模型附带特色标签。
二、可视化展示
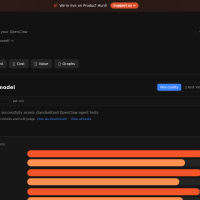
平台以极简的榜单形式呈现结果:
- 文字榜单:按成功率降序排列,标注模型名称、成功率,优质模型附带专属图标。
- 表格榜单:包含模型名称、提供商、成功率、综合得分四列,便于对比。
最新评测结果亮点
平台数据于2026年3月11日更新,涵盖Anthropic、OpenAI、英伟达、月之暗面、通义千问、智谱AI等数十家厂商的模型,核心亮点如下:
- 头部模型被Anthropic垄断:anthropic/claude-sonnet-4.6以86.9%的成功率位居第一,anthropic/claude-opus-4.6以86.3%位列第二。
- OpenAI高端模型表现优异:openai/gpt-5.4以86.0%的成功率排名第三,成为OpenAI系表现最好的模型。